[Paper Review] Dynamic Prototype Network Based on Sample Adaptation For Few-Shot Malware Detection
최근, 연구실 내 세미나 준비 및 대외활동 프로젝트 진행으로 인해 Paper Review 및 악성코드 관련되어 포스팅을 거의 하지 못하였다.😭 지난 포스팅(Paper Review: Feature Selection For Malware Detection Based on Reinforce ment Learning)에 이어 2번째 Paper Review이지만, 앞으로는 이때까지 포스팅하지 못한 논문들과 악성코드(최근 동향 및 분석?)와 관련된 내용으로 포스팅하고자 한다.
이번에 분석한 논문은 Dynamic Prototype Network Based on Sample Adaptation For Few-Shot Malware Detection이며 2023년 5월 IEEE Transactions on Knowledge and Data Engineering Journal에 투고되었다.

1. Motivation
본 논문은 일반적인 Random Forest(이하 RF), CNN을 통해 악성코드를 분류하는 것이 아니라, Few-Shot Learning(이하 FSL) 기반 모델을 활용하여 악성코드 분류 문제를 해결하였다.
왜 FSL 방식을 사용하여 분류 문제를 수행하였을까? 여러 연구에서 기존 일반적인 모델을 활용한 악성코드 분류 문제의 정확도가 99%에 도달하였음에도 불구하고 2가지의 한계점이 존재한다.
기존 일반적인 모델(RF, CNN 등)의 2가지의 한계점 ⚠️
1. 사전에 정의된 특정 클래스의 샘플들이 필요하며 이를 기반으로 하여 학습을 진행한다.
2. 기존 모델들에 Few(적은)한 데이터를 Input 데이터로 사용할 경우 성능이 저하된다.
이러한 한계점을 해결하기 위해서는 모델 자체가 단순히 주어진(or Target)클래스를 잘 분류하도록 학습하는 것이 아니라 분류하는 방법을 배워 새로운 클래스의 Few 한 데이터가 Input 데이터로 사용되더라도 좋은 성능을 도출할 수 있도록 해야 한다. 즉, 분류하는 방법을 배우는 것인데 이러한 학습 방법이 FLS 과 Meta Learning이다.
추가적으로, 본 논문에서는 같은 패밀리나 클래스일지라도 모든 피처를 동일한 활성화함수에 사용할 경우 성능에 저하되는 피처 또한 학습하게 되는 문제를 해결하기 위해 기존 FSL 모델에 샘플 적응형 동적 피처 추출 부분을 결합한 형태의 모델(Dynamic Prototype Network based on Sample Adaptation for few-shot malware detection, DPNSA)을 제안하였다.

2. Methodology
본 논문에서 제안한 방식(DPNSA)의 Architecture는 Figure 2와 같다. 크게 Malware Image, Embedding, Prototype Calculation, Dual Sample Dynamic Activation, Metric Learning(Classification)과 같이 5개의 모듈로 구성되어 있으며 최종적으로 Classification을 수행하게 된다.

2.1 Malware Image Module
해당 모듈은 Malware Sample을 256*256 Gray-Scale Image File로 변환하는 모듈로, 실험에 사용한 Malware Sample은 Reference의 Tang 등의 연구와 동일한 방식으로 필터링을 진행한 Virustotal 데이터를 사용하였다. 최종적으로 변환된 Gray-Scale Image 예시는 Figure 3과 같다.

2.2 Embedding Image Module
해당 모듈은 Support Set의 각 클래스마다 Embedding Feature를 추출한다. FSL에서 소수의 Sample을 사용하면서 모델 자체의 파라미터가 많을 경우 과적합이 발생할 가능성이 존재하게 되는데, 이를 해결하기 위해 A light weight Network를 사용하였다. 또한 Dynamic Convolution Layer 및 Sqeeze and Excitation 방식을 통해 보다 연관성이 높은 Feature가 추출되도록 한다.


2.3 Prototype Calculation Module
해당 모듈은 Support Set의 각 클래스의 모든 샘플의 Dynamic Embedding 평균을 계산하는 모듈로 해당 모듈에서 계산된 값을 각 클래스의 Prototype으로 사용한다. 각 클래스의 Prototype을 계산하는 방법은 Figure 6과 같다.

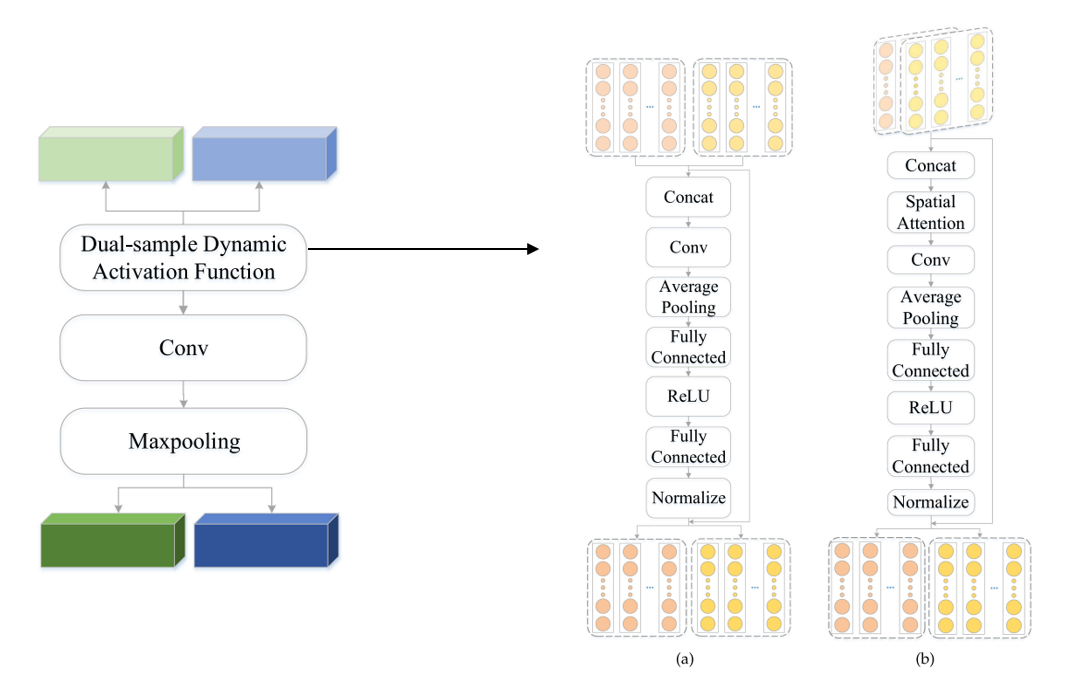
2.4 Dual Sample Dynamic Activation Module
해당 모듈은 Query Sample와 Support Set의 Prototype에 따라 동적으로 기울기 및 상수가 변경되어 동적 활성화함수에 학습하는 역할을 한다. 샘플에 따라 동적 활성화 함수가 적용된 후에는 Convolution 및 Maxpooling을 거쳐 최종적인 벡터가 생성된다. Dual Sample Dynamic Activation Module의 Architecture는 Figure 7과 같다.
2.5 Metric Learning Module(Classification Module)
해당 모듈은 Dual Sample Dynamic Activateion Module에 의해 생성된 Query 및 Prototype의 Feature 사이의 Distance를 계산하여 유사도를 판단한다. 이때, Distance는 Cosine Distance Metric를 사용하여 측정한다.
3. Experiment
Meta Training Set에는 100개의 클래스, Meta Validation Set에는 58개의 클래스 Meta Test Set에서는 50개의 클래스로 구성되어 있으며, 각 클래스당 20개의 샘플로 구성되어 있다. Meta Training 단계에서는 100개의 에피소드로 구성하고 각 에피소드는 Support Set에서 N-way K-shot 무작위 샘플링을 통해 진행한다. 또한, 실험을 진행할 때 Parameter Value는 Figure 8과 같다.

실험 결과는 Figure 9와 같으며 CL은 기존 Classic 한 모델, O는 Meta Learning 중 Optimization Based 모델, M은 Metric Based 모델을 의미한다.
동일한 데이터 셋을 사용한 타 연구에 비해 본 논문에서 제안한 프레임워크(DPNSA)는 5-way-5-shot에서 19.53%, 5-way-10-shot에서 15.10% 정확도 향상이 있었으며 10-way 그리고 1-shot을 사용한 경우에도 정확도가 향상된 것을 볼 수 있다.



4. Conclusion(개인적인)
본 논문 Review를 하고 난 후 가장 먼저 한 생각이 동적 활성화 함수가 보다 다양한 모델에도 적용할 수 있을까?이다. 개인적인 생각으로 만약 다른 모델에도 동적 활성화 함수 방식이 적용된다면 보다 샘플에 맞게 기울기 및 상수가 변경되기 때문에 성능 향상은 필연적으로 이어진다고 생각한다.
또한, 추후 Few-Shot Learning 및 Meta Learning에서 Metric Based Model, Optimization Based Model에 대해서도 학습할 예정이며 악성코드와 관련되어 Feature Extraction 방식에 차이를 둔 논문에 대해서도 Review 할 예정이다.