[Paper Review] Feature Selection for Malware Detection Based on Reinforcement Learning
최근, 새로운 연구 주제 선정 겸 ML 및 DL을 사용한 악성코드 탐지 방법 동향이 궁금해져 논문 Review를 시작하였다. 기존에도 몇몇 논문들을 분석하였으나, 기록들을 하지 않았고 그로 인해 어떤 논문을 분석했는지 알 수 없어 기록하고자 한다.
이번에 분석하고자 하는 논문은 Feature Selection for Malware Detectiona Based on Reinforcement Learning이며 2019년에 IEEE Access에 Publish되었다. 추가적인 논문 정보는 아래와 같다.
https://ieeexplore.ieee.org/document/8920059
Feature Selection for Malware Detection Based on Reinforcement Learning
Machine learning based malware detection has been proved great success in the past few years. Most of the conventional methods are based on supervised learning, which relies on static features with labels. While selecting static features requires both huma
ieeexplore.ieee.org
1. Introduction
기존의 악성코드 탐지를 위해 활용하는 정적 Feature로는 Signature, Format Structure, Raw Binary가 존재한다. 하지만, 위에서 나열한 정적 Feature를 활용할 경우 아래와 같은 문제점에 직면할 수 있다.
직면할 수 있는 문제⚠️
1. Feature Extractiong 단계는 자동적으로 수행되지 않으며 주로 사람의 경험에 의존
2. 추출된 Feature가 샘플의 주된 특징을 포괄적으로 포함하지 못함
3. 광범위한 지표 및 Feature는 더 좋은 성능을 도출할 수 있지만, 학습 속도가 느려지며 중복이 발생할 수 있음
본 논문에서는 이러한 문제점들을 해결하기 위해 Q-Learning, Deep Q-Learning(DQL)을 사용한 프레임워크 Deep Q-Learning based Feature Selection Architecture(DQFSA)를 제안하여 자동적으로 최적의 성능을 도출하는 피처를 자동적으로 선택하고 인간의 개입을 최소한으로 하여 악성코드 분류 문제를 해결하고자 한다.
2. Related Work
본 논문에서는 관련 연구 부분에서 관련 연구의 성능 및 구체적인 이름을 명시하였으나, 본 Review에서는 관련 연구의 성능보다는 다양한 Static Feature들(Signature-based, Static Structured Features and Format Features, N-gram Features)의 방식 및 단점 관점에서 서술하고자 한다.
2.1 Signature-based
Signature-based Feature는 가장 흔하게 접하는 Feature 중 하나이다. 악성코드 탐지에 있어 가장 흔하게 사용하는 MD5, SHA-1, SHA-256과 같은 Hash 값도 이에 해당되며 Yara Rule 또한 이에 해당된다. 해당 방식은 지정된 Signature정보를 토대로 악성 여부를 판단하게 되지만 새로운 악성코드 및 변종은 탐지하지 못한다는 단점이 존재한다.
2.2 Static Structed Features and Format Feature
해당 방식은 정상적인 소프트웨어와 악성 소프트웨어는 구조적인 차이가 존재한다는 점에서 고안된 Feature이다. 하지만, 몇몇 구별되지 않는 소프트웨어가 존재하게 되는데 이러한 소프트웨어들로 인해 성능이 저하된 경우가 다수 존재한다. 또한, 해당 Feature를 추출할 때 도메인 지식이 추가적으로 필요하다는 단점이 존재한다.
2.3 N-gram Features
파일 내 존재하는 String 정보를 N(수)단위로 묶어 SubString(SubSequence)를 생성하는 방식으로 N-gram 기반 LSTM 모델 등과 같은 다양한 연구가 존재한다. 하지만, 최고 정확도는 90%로 좋지 못한 분류기 성능이 도출되었다는 단점이 존재한다.
3. Proposed Framework
본 논문에서 제안한 DQFSA 모델은 Data Collection and Preprocessing, Original Features Extraction, Reinforcement Learning-based Training 3단계로 구성되어 있으며, 구체적인 Architecture는 Figure 1과 같다.
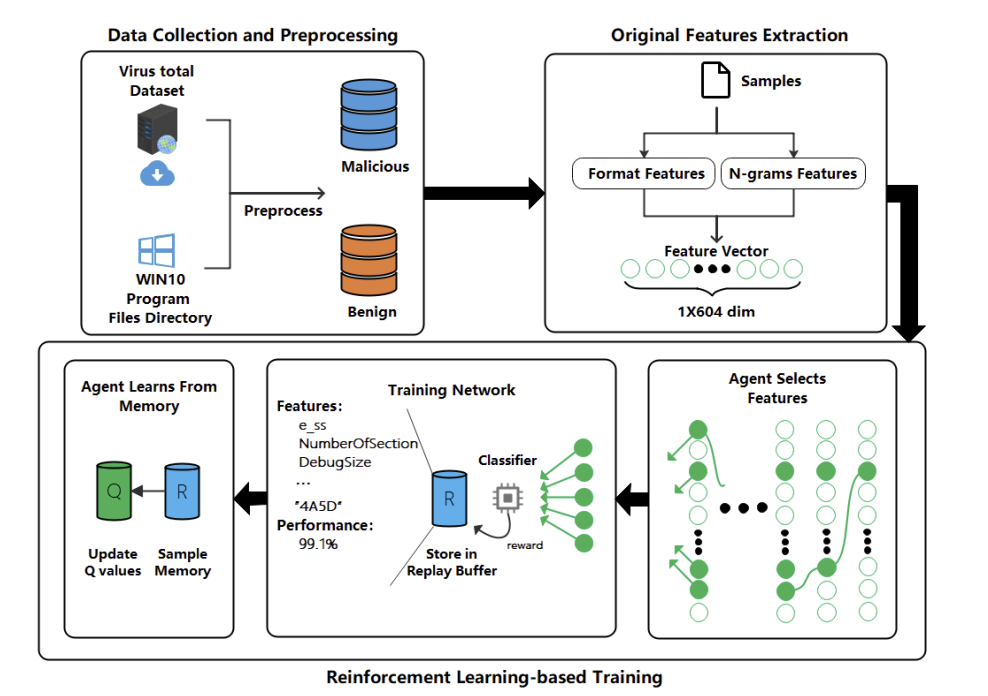
각 단계를 세부적으로 살펴보자.
3.1 Data Collection and Preprocessing
첫번째로 수행하는 단계이며, 단계의 이름에서 유추할 수 있듯이 데이터를 수집하고 전처리하는 단계이다. 악성 샘플(Malicious)의 경우 ViusTotal 사로부터 수집하였으며 수집된 샘플의 개수는 12,146개이다. 정상 샘플(Benign)은 Windows 10의 Program Files Directory로부터 수집하였으며 수집된 샘플의 개수는 9,057개이다. 이때, 다른 데이터 가공 모듈에 의해 가공되어진 샘플은 실험에서 제외되었다.
3.2 Original Features Extraction
해당 단계는 이전 단계에서 수집한 샘플로부터 Feature를 추출하고 Reinforcement Learning 모델에 활용할 Input데이터로 변환하는 단계이다. 본 실험된 Feature는 크게 Format Features, N-grams Features로 구분된다.
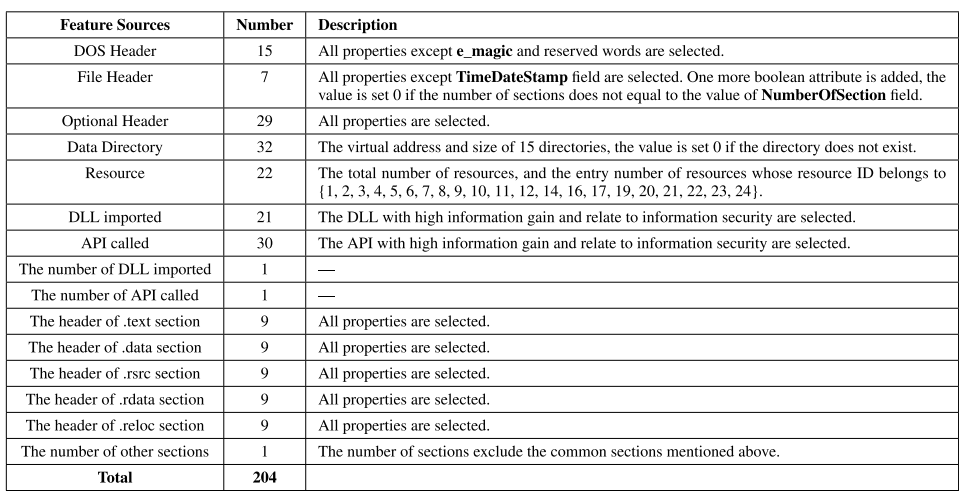
3.2.1 Format Features
구조적인 특징에서 추출된 Feature로 Python 라이브러리인 pefile toolkit을 사용하였으며 최종적으로 추출된 Feature는 Figure 2와 같다.
3.2.2 N-gram Feature
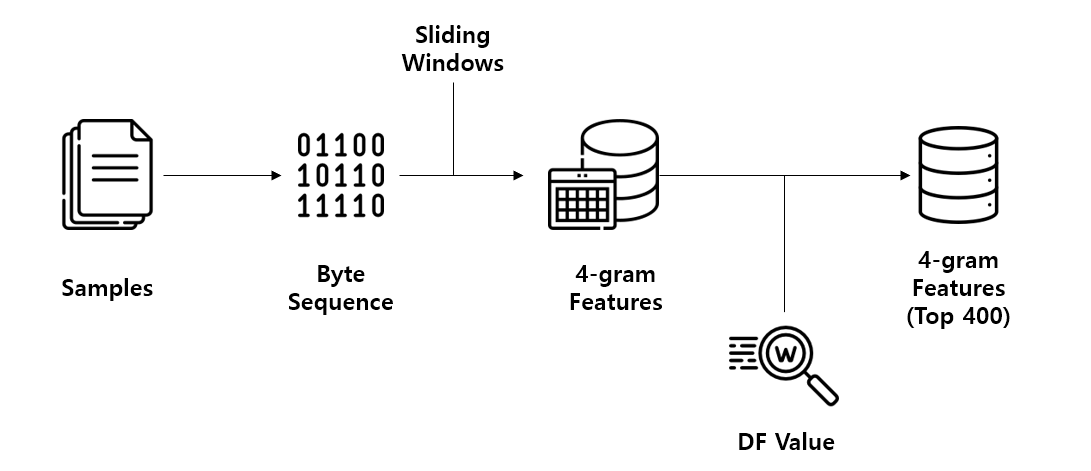
N-gram은 샘플에서 존재하는 Byte Sequence, String 정보를 N(수)를 기준으로 SubString을 만드는 방식을 말한다. 즉, 1,2,3,4,5,6,7 이라는 String Sequence가 존재할 때, N이 3이라면 123, 234, 345, 456, 567과 같은 형태로 SubSequece로 만드는 것이다.
본 논문에서 N의 값은 4로 고정하였으며 Sliding Window를 활용하여 추출된 4-gram Byte Sequence에서 DF Value가 높은 400개의 4-gram Byte Sequence만을 최종 N-gram Features로 활용하였다. 구체적인 과정은 Figure 3과 같다.
3.3 Reinforcement Learning-based Training
해당 단계는 Agent가 샘플의 정상 및 악성 여부를 판단하기 위해 특정 Feature를 선택하는 과정이다. Agent가 특정한 Feature를 선택한다면 환경이 보상(=선택한 Feature의 분류 정확도)를 제공하고 선택한 Feature 및 분류기의 성능이 Replay 버퍼에 저장된다. 이후, Agent는 저장된 내용을 토대로 하여 공간적인 특징을 학습하고 실제 학습 및 평가가 이루어진다.
4. Experiment and Result
본 논문에서 실험은 크게 분류기를 기준으로 성능을 평가한 Comparision with different classifiers, 관련 연구와 동일한 데이터셋을 사용하였을 때의 성능을 평가한 Comparision with related work로 이루어졌다.
Comparision with different classifiers 실험에서는 보다 성능을 쉽게 확인하기 위해 Feature의 수는 5~15개로 제한하였으며 11개의 Feature가 사용되었을 때 대부분의 분류기에서 99%성능에 도달한 것을 확인할 수 있다. 그 중, KNN 모델에서 제일 좋은 성능을 보였다.

Comparision with related work 실험에서는 관련 연구와 동일한 데이터 셋을 사용하여 실험을 진행하였으며, 본 논문에서 제안한 프레임워크(DQFSA)의 성능이 더 우수한 것을 확인할 수 있다.

5. Conclusion
본 논문 Review를 통해 Feature Selection에 있어 보다 다양한 관점에서 생각할 수 있게 되었으며, Feature Selection과정에서 강화학습을 통해 자동적인 Selection가 이루어지는 것에 있어 좋은 아이디어라고 생각하였다. 단순히, 학습하는 과정에서만 차이를 둔 연구가 아닌 전반적인 과정에서 또 다른 아이디어를 제시하여 연구를 진행하는 것도 하나의 방법이라고 생각하게 되었다.
본 논문과 관련된 코드는 아래의 링크에서 확인할 수 있다.https://github.com/fanmcgrady/select-features
GitHub - fanmcgrady/select-features
Contribute to fanmcgrady/select-features development by creating an account on GitHub.
github.com